

Retrieval Is Not Understanding
I am a few months late to talking about context graphs, and about a decade late to mentioning proof of work. This is not ideal timing, but it does put me in the right emotional posture: suspicious, slightly embarrassed, and therefore willing to ask the boring question.
What, exactly, is a context layer?
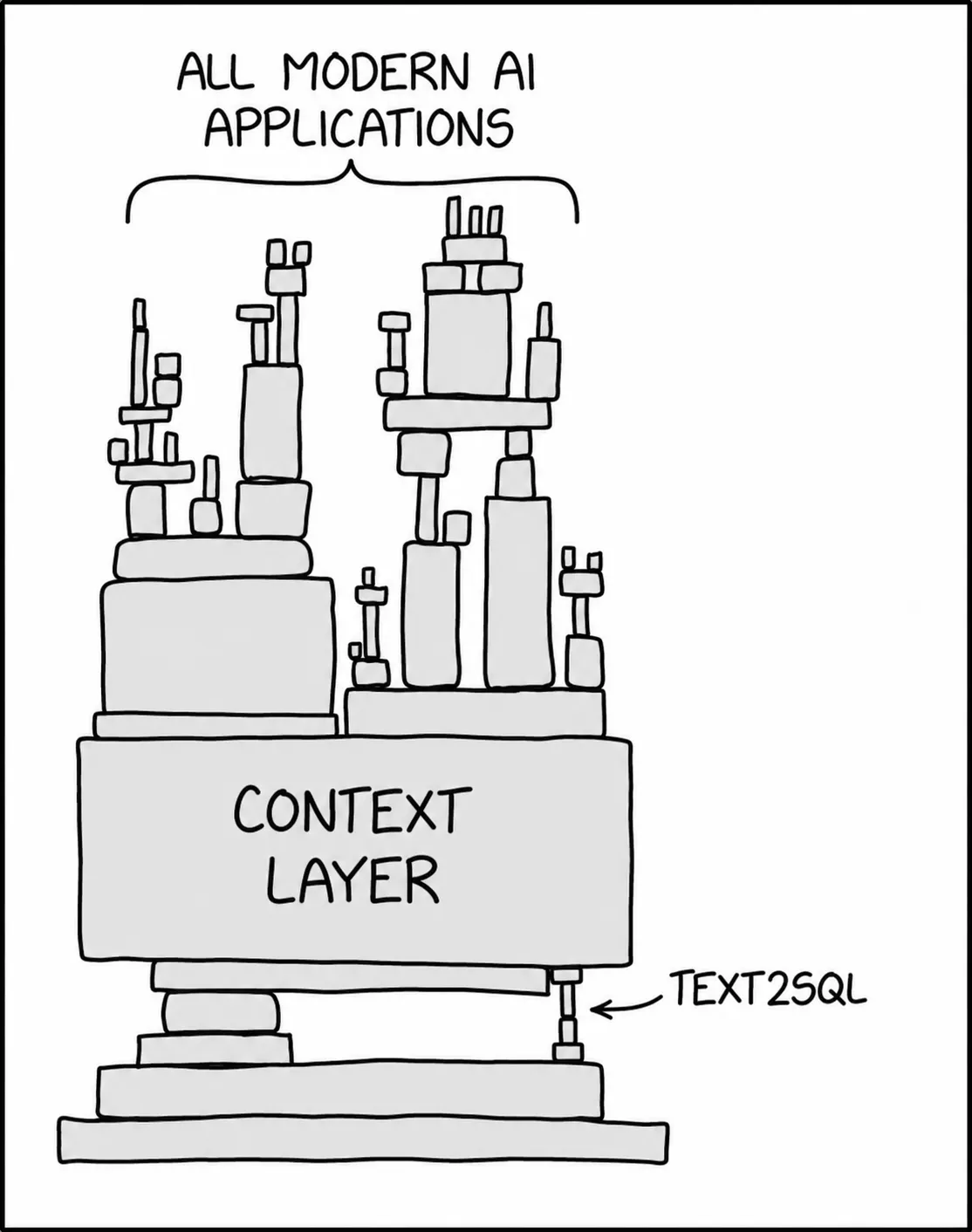
Every B2B AI startup now has some version of the same promise. Connect Slack, Notion, Drive, Salesforce, GitHub, Jira, Linear, support tickets, call transcripts, email, and the ancient Google Doc whose title is just "Q3 plan final final v7." The agent will read everything. It will build a context graph. It will know what your company knows.
Sure. Fine. Agents need context. But the phrase has gotten too easy.
Last year you had a Notion workspace no one trusted, a Slack history no one could search, and a Salesforce instance maintained through guilt, optimism, and end-of-quarter archaeology. This year, after embeddings and three connectors, the same pile has been promoted to "the context layer."
Better than nothing.
Not yet a brain.
A chatbot over your documents is not company knowledge. Most of these systems can retrieve an artifact. They cannot yet tell whether they have found memory, evidence, theater, or residue.
Was this a proposal or a decision?
Was it true when written?
Is it still true?
Did anyone implement it?
These questions are annoying because the answers rarely live inside the document itself. They are spread across systems, timestamps, decisions, implementation traces, and people, some of whom no longer exist within the org.
AI Broke the Old Proof-of-Work Signal
Internal knowledge was never pure.
Corporate docs have always contained theater. Planning docs drift. Strategy memos age badly. Sales decks overstate capabilities. Customer notes go stale. Slack threads preserve the emotional state of whoever typed fastest.
I do not want to romanticize the pre-AI wiki. The old knowledge base was not a temple. It was a supply closet with labels.

But the old system had one useful property: polished artifacts were expensive enough that effort acted as a rough trust signal.
If someone wrote a serious proposal, it usually meant they had spent time. They had used reputation. They expected review. They had to defend tradeoffs in front of people who knew enough to object. An architecture doc did not guarantee wisdom, but it often implied that someone would be available later to explain why the ugly part was ugly.
There was proof of work: elapsed time, ownership, review, scar tissue, and the quiet fear of being wrong in front of your peers.
AI weakens that signal.
Now you can fill the wiki with plausible artifacts. Meeting summaries, product briefs, strategy drafts, onboarding pages, competitive analysis, customer recaps, implementation plans. Smooth prose. Familiar headings. Reasonable tradeoffs. A confident tone.
The document looks finished. To a novice, it feels insightful. To an expert, it may be a waste of storage, time, and tokens.
The Receipt Layer: Where Agents Check the Story
Imagine you are the agent. You can access every document, every Slack thread, every ticket, every version of every plan. This sounds like a superpower until the task becomes deciding what to believe.

Similarity is not authority. Vector search can tell you what text is nearby. It cannot tell you whether that text survived contact with reality.
A useful context layer therefore needs more than retrieval. It needs some way to resolve conflict, age out stale claims, and check polished memory against operating evidence.
We've known forever about stated preferences vs observed preferences.
There is the narrated company: the one in strategy docs, planning decks, meeting notes, policies, onboarding pages, and Slack threads.
Then there is the operating company: the one in CRM stages, product events, invoices, discounts, support tickets, warehouse tables, approval logs, renewal dates, implementation hours, and pipeline movement.
The narrated company tells you what people believe, intend, promise, remember, and would prefer to be true.
The operating company shows you what is happening. This is where text-to-SQL becomes interesting: not as a nicer BI interface, but as a way for agents to test the narrated company against the operating one.
The agent sees a doc that says enterprise renewals require executive sponsor review. Before starting outreach, it asks the systems:
Which accounts renewed in the last 60 days?
How many of them have an executive sponsor mapped?
Are there signs in the transactional history that indicate that the renewal date moved around because of manual approvals?
The SQL is not the intelligence. It is the receipt.
This is why text-to-SQL becomes load-bearing in agent systems. It gives the agent a way to move from "I found a relevant artifact" to "I checked whether the business is behaving as if this artifact is true."
Without that check, the context layer becomes a library of intentions.
We keep saying "context layer" as if context is one substance.
It is not.
There is memory context: durable artifacts that explain how the company thinks, speaks, decides, and intends to operate.
Then there is evidence context: live or recent signals from systems that show what the company is actually doing.
Agents need both, but they need them labeled differently. A strategy memo, a support escalation, a signed contract, a usage table, and a roadmap promise should not enter the model as equivalent pieces of nearby text.
The real context layer is not the place where all company information goes. It is the system that helps an agent understand what kind of information it has found, how much to trust it, and what would count as a receipt.